Loading…
← Back to Thinking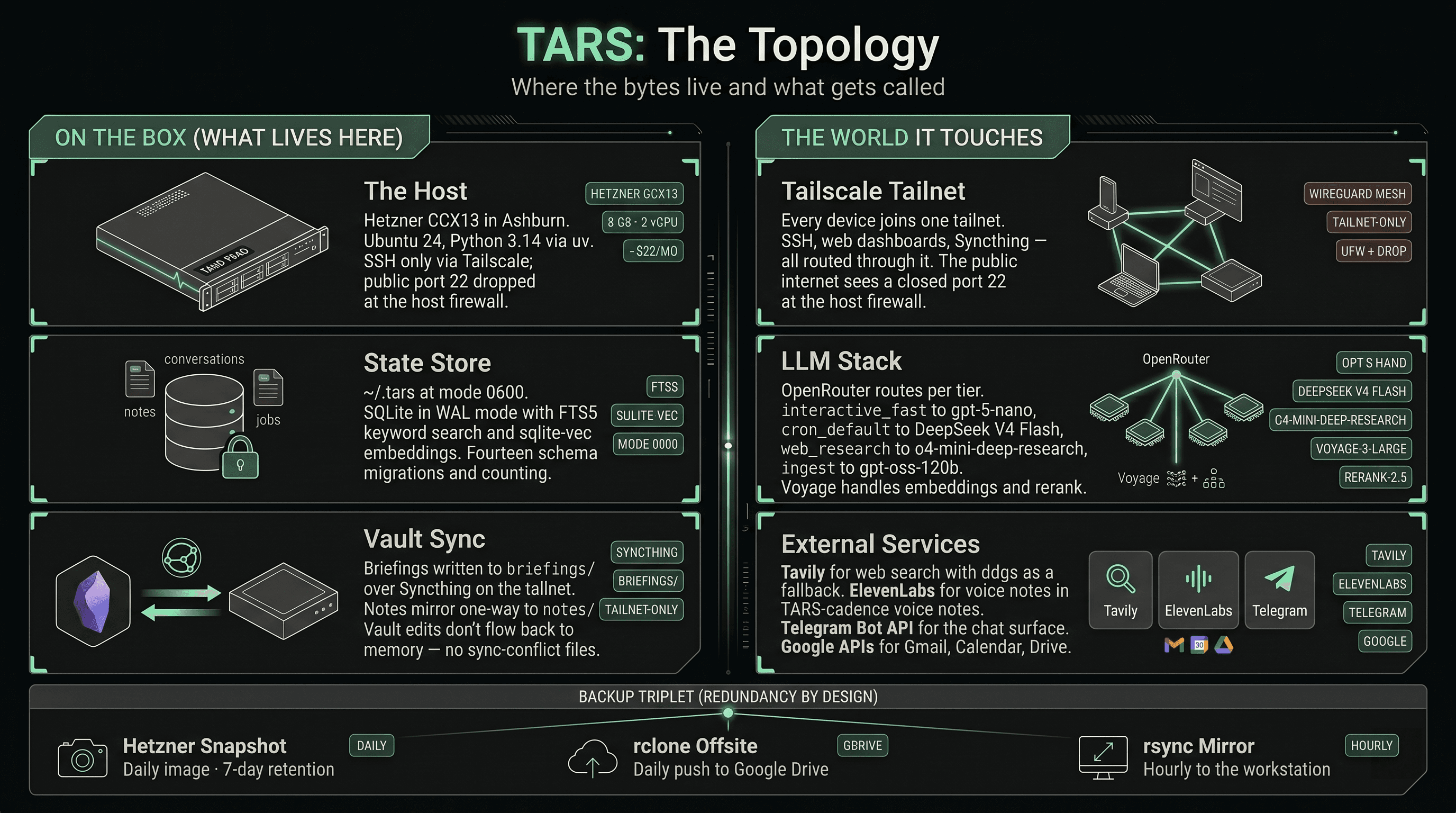


Meet TARS
The 5 AM voice note that ships my day
5:00 AM. My phone buzzes. It's a Telegram voice note in TARS-from-Interstellar's deadpan cadence: overnight headlines I asked it to track, top items on the calendar, two open follow-ups from yesterday I haven't closed, and a heads-up that a player I watch pushed a release at 02:17.
I haven't checked email yet. I haven't opened a single browser tab. The day is already framed.
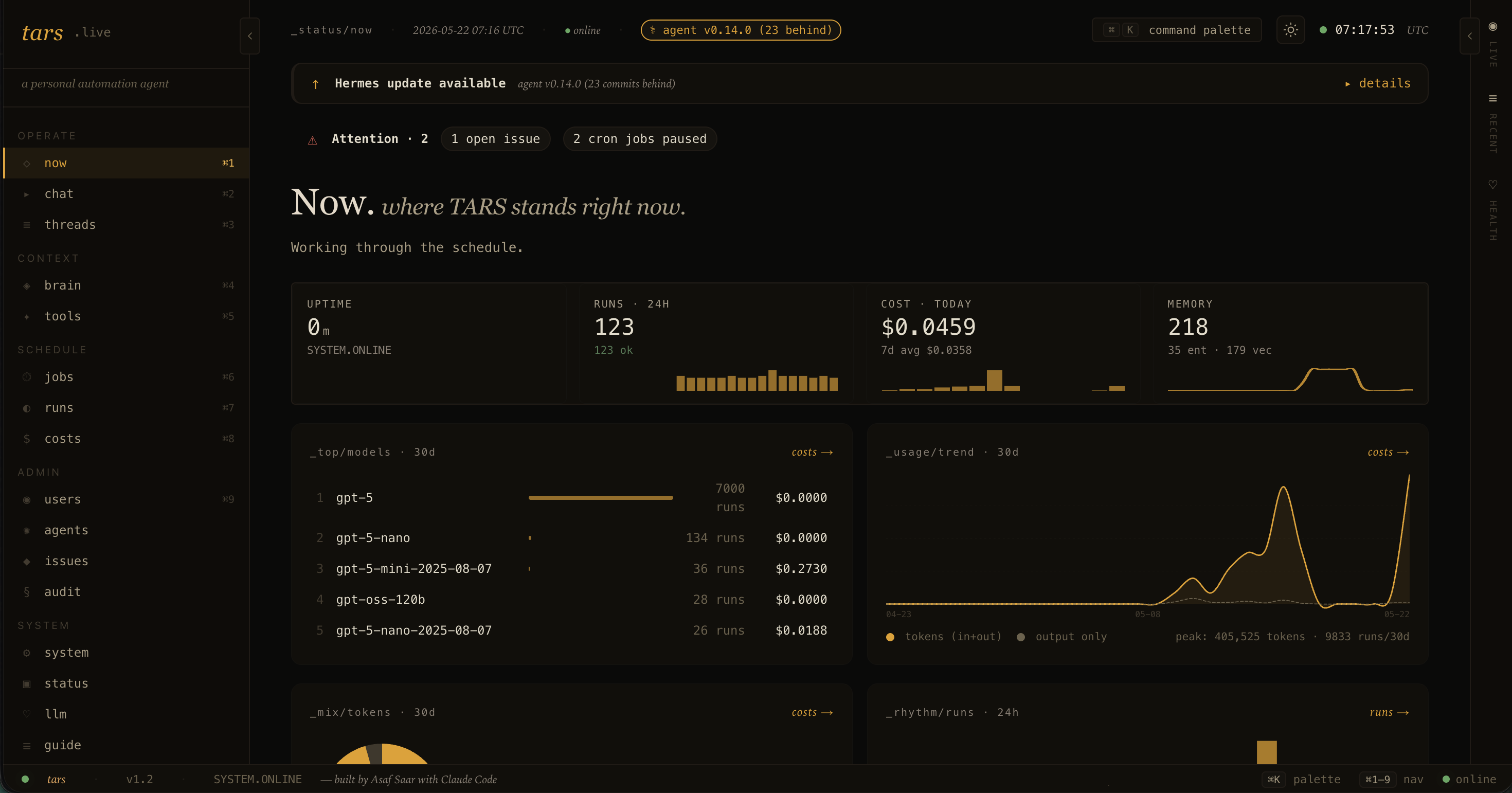
That's the agent. His name is TARS. He runs on a small Hetzner VPS, reachable only over Tailscale. He answers Telegram, fires about eighteen scheduled jobs, holds a SQLite memory of every note and conversation I've had with him, and pings me when something I asked him to watch actually moves. He cost me roughly two weekends to V1 and now costs about $22 a month for the box plus a few dollars a day in LLM tokens.
This is the story of why I built him, what he does, and the architectural choices that made the difference between a demo and a system I rely on.
 Left: what it does for me. Right: why it actually works.
Left: what it does for me. Right: why it actually works.
A personal automation agent that runs my day. Eighteen scheduled jobs, one SQLite memory, a Telegram presence, and a voice that sounds like the original. Two weekends to V1. Three substrates and counting.
What I wanted, and what nobody was selling
Everyone has access to frontier models. Almost nobody has access to their own model that knows them.
The chat apps are stateless. Every conversation starts from zero. The "memory" features are shallow summaries of past chats. The agent frameworks are sprawling and built for someone else's workflow. The note-taking tools don't reach out. The cron-driven scripts don't talk back. The smart-speaker assistants can set a timer and turn off a light.
I wanted one thing that did all of it: a persistent, scheduled, conversational, opinionated agent with a memory it actually used and a voice I'd actually listen to. Something that could read my email, prep my morning, watch the markets I track, take notes when I asked, surface follow-ups I'd promised someone last week, and stay out of my way the rest of the time.
So I wrote it. Twice.
What TARS actually does
In one sentence: TARS is a personal automation agent that lives on a Telegram thread, runs scheduled jobs, persists everything to a local SQLite memory, and gets out of my way.
The capabilities I actually use, every day or close to it:
Morning briefing at 05:00. A short Telegram message: overnight email, the calendar, top news in domains I care about, any open follow-ups from yesterday's notes. Sometimes a voice note when I ask for one.
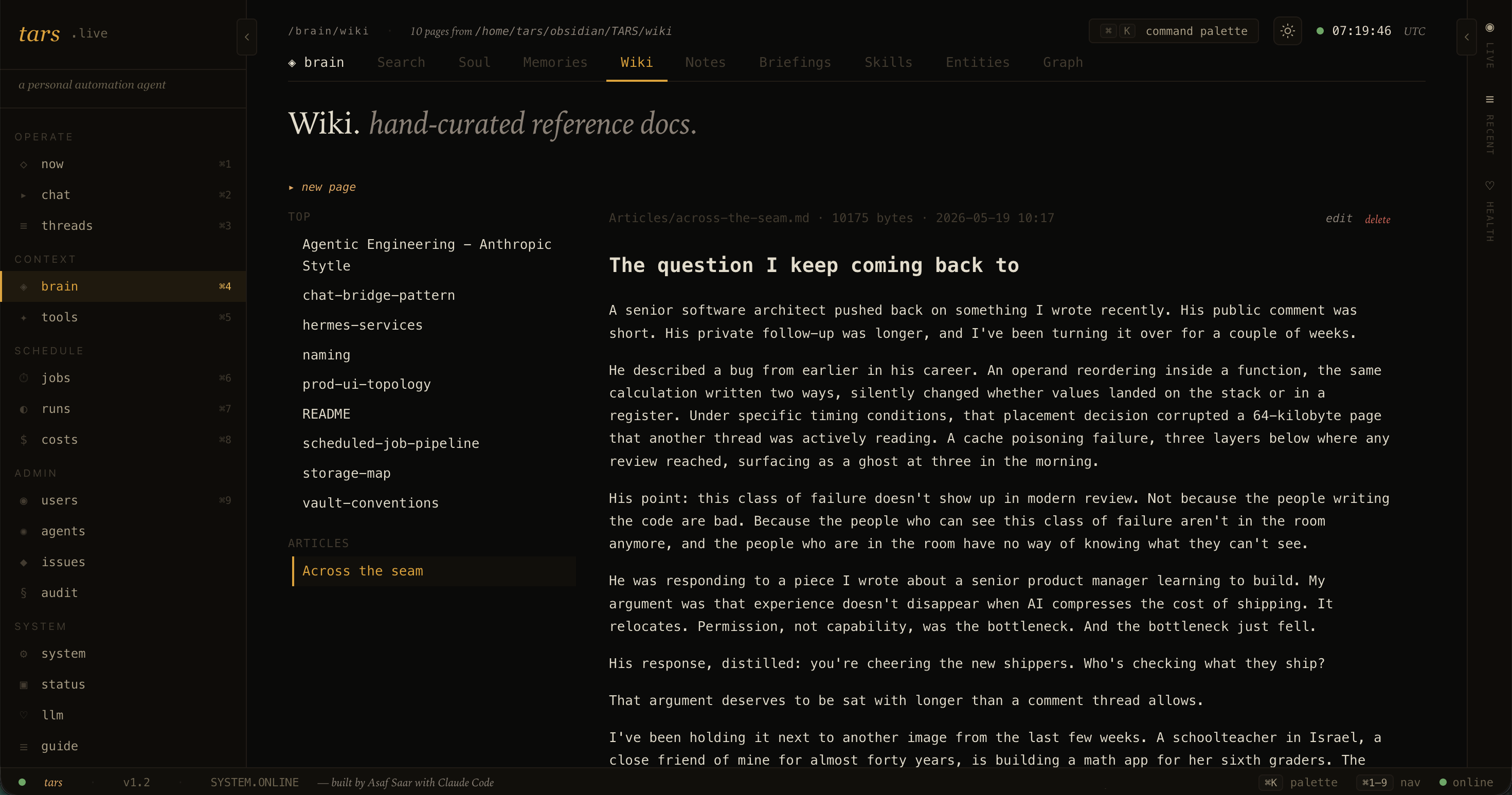
Persistent note-taking. I type "note: that idea about..." in Telegram and TARS saves it with auto-extracted entities and tags. Hybrid keyword plus vector search ("did I write anything last month about routing model selection?") finds it later. The notes also mirror to an Obsidian vault subdir over Syncthing, so anything I save shows up on my desktop too.
Follow-up lifecycle. Notes can be open or closed. Weekly summary jobs reconcile against memory and reopen things I promised that didn't ship. Closing a follow-up requires a citation against the resolving note, so the agent can't hand-wave anything to a green check.
Competitive intelligence. Scheduled scans of the markets I track. Silent on quiet days. Weekly heartbeat on Sundays. When something moves, the message arrives before my coffee does.
Deep research on demand. A chat command kicks off a bounded tool-loop over web and memory and returns a single coherent answer instead of a list of links.
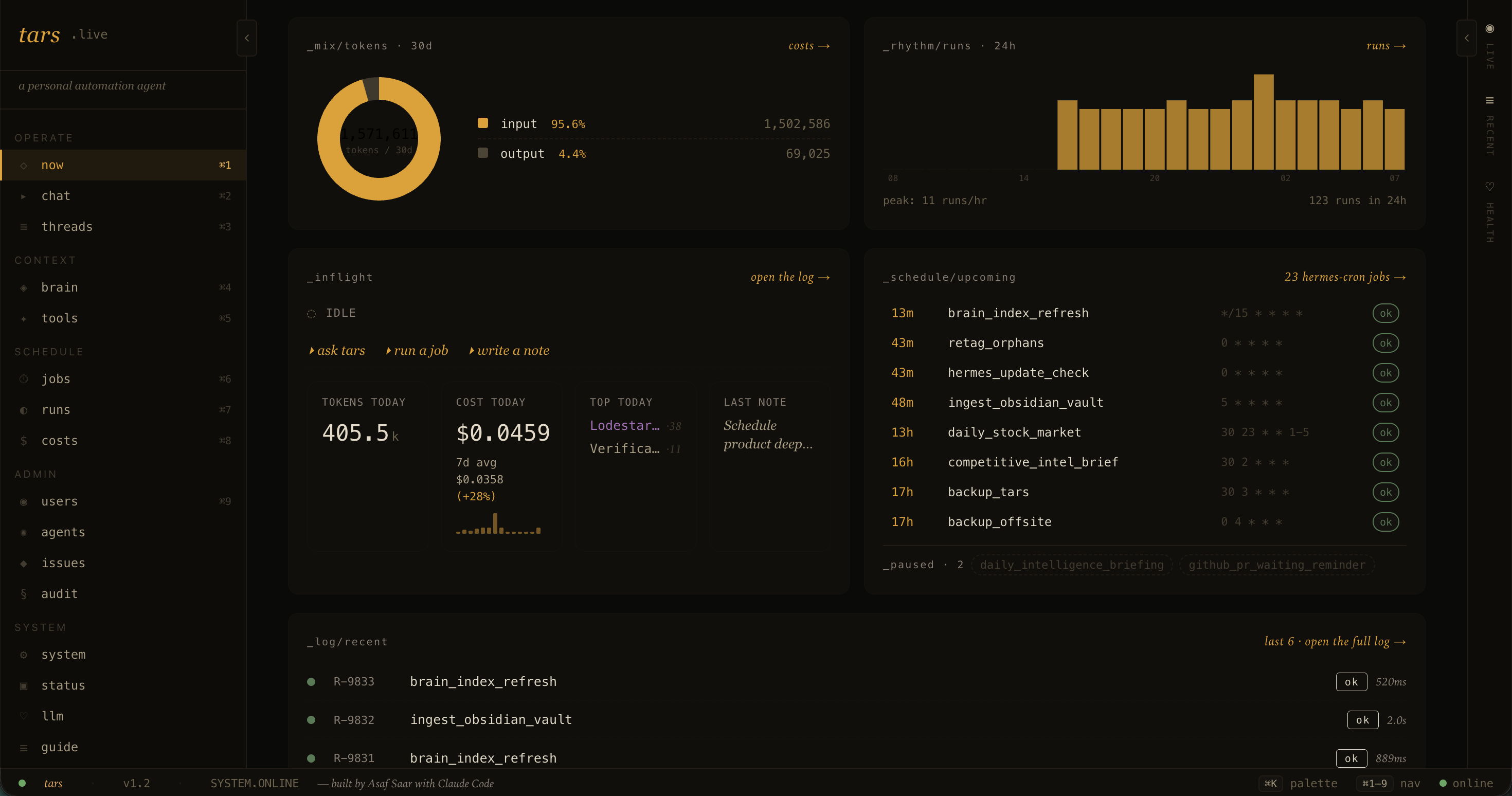
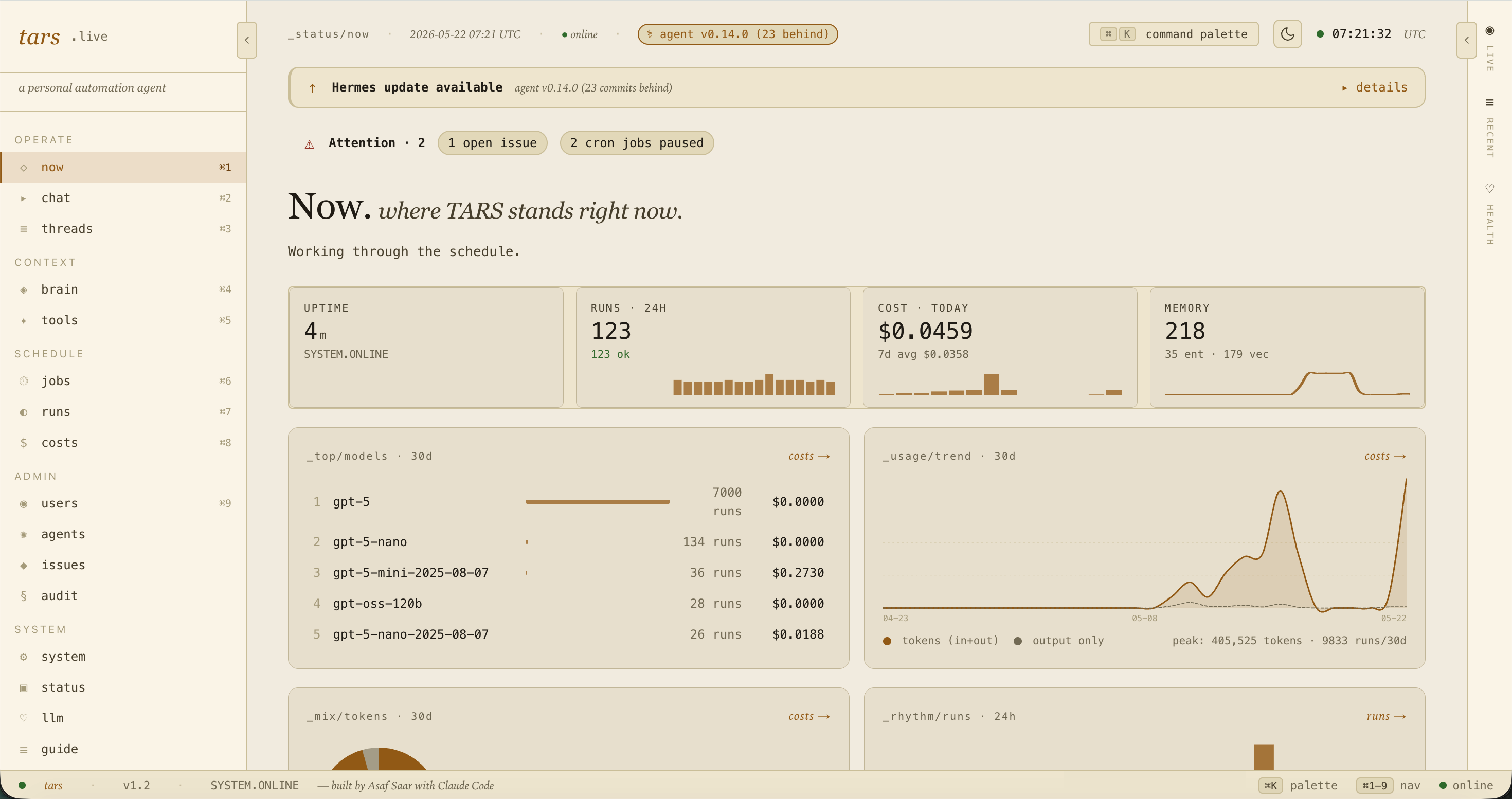
Tailnet-only web dashboard. Cost rollups by job, model, and tier. An in-flight job rail driven by Server-Sent Events. A search across every conversation I've ever had with the agent. A unified read-only view of every memory file the agent loads at boot.
A voice persona. When I want it, the chat reply is also synthesized to OGG and arrives as a Telegram voice note in TARS-from-Interstellar's cadence. It's off by default per chat. It costs intent.
He talks to me in TARS's voice when I want, in plain text when I don't.
The architectural choices that mattered
Most of what makes TARS work is not in the prompts. It's in the system shape.
One server, six external dependencies, three backup destinations.
One process. One Agent. One Memory. The Telegram bot, the scheduler, and the FastAPI dashboard all run in the same asyncio loop, sharing one Agent instance and one SQLite handle. No cron daemon, no IPC, no message queue. Everything that needs state goes through the same object graph.
Stateless agent, stateful memory. The Agent class holds zero per-conversation state. Conversation history lives in SQLite, indexed by a thread key (tg:{chat_id} for Telegram, job:morning_briefing for the morning job, web:asaf for the dashboard chat). The same Agent serves every surface without any of them stepping on each other.
The system prompt is a cache anchor. Assembled once at module import, frozen for the life of the process, byte-identical every call. Tool schemas serialize the same bytes every turn. History appears at the tail. OpenRouter routes a portion of the prefix-cache discount back through, and the cache hit rate is visible in response headers. This is the single biggest determinant of latency on a small agent. Far more than which model you picked.
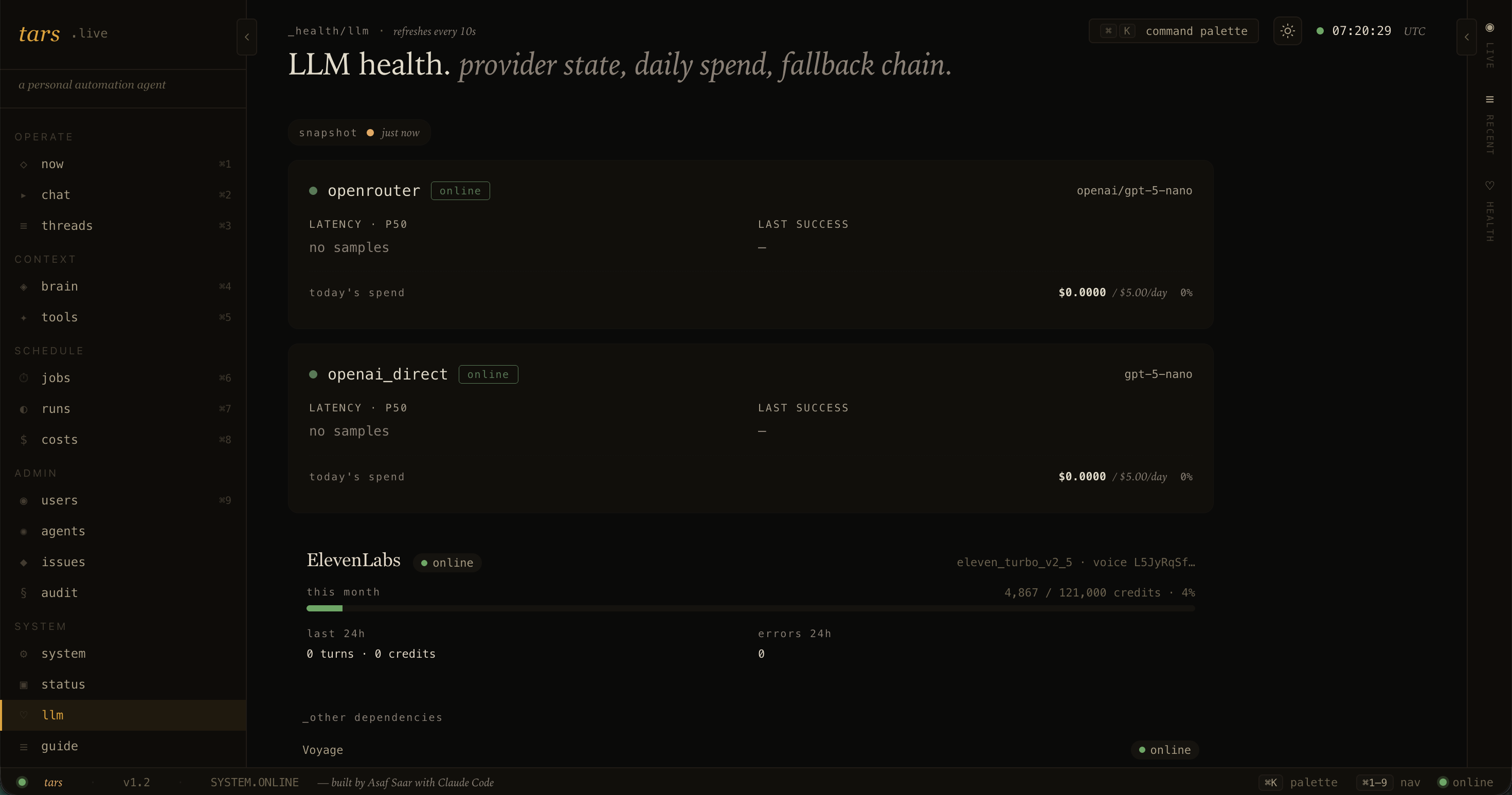
Cloud-only LLM, multi-tier routing. No local Ollama. Every call site declares a tier. interactive_fast for chat. cron_default for scheduled jobs. ingest for high-volume bulk work. web_research for the deep research tool. Each tier maps to a model. When DeepSeek V4 Flash showed parity at 10 to 43 times lower cost on the cron jobs, I promoted it for those tiers and kept gpt-5-mini as a per-job rollback lane. The router runs OpenRouter primary with OpenAI direct as fallback, with per-provider daily spend caps and 60-second cooldowns on 5xx and 429.
Hybrid retrieval. SQLite with FTS5 for keyword, sqlite-vec for vectors, Voyage voyage-3-large for embeddings, Voyage rerank-2.5 for reranking with a graceful identity fallback when the free tier rate-limits. A unified brain_docs FTS index is rebuilt every 15 minutes across notes, conversations, briefings, and the vault.
Single source of truth. Code on origin/main. Deploy script pushes to prod and that's it. Rollback is git revert. Secrets in a 0600-mode TOML file in ~/.tars/, never in git. The whole system is auditable in an afternoon.
TARS isn't OpenClaw, and TARS isn't Hermes
I get this question a lot from people who watched me ship "Cloud Is the Brain. Local Is the Hands. Stop Choosing." earlier this year. If TARS is Hermes Agent and CASE is OpenClaw, isn't TARS just "the Hermes one"?
Not really.
Both OpenClaw and Hermes Agent are agent frameworks. They give you a chat loop, a tool-calling protocol, a system prompt scaffolding, an opinionated runtime. They are interchangeable substrates. I have run TARS on three different ones over the past six months: a Hermes Agent install on my workstation, a from-scratch Python agent on the same box, and the current setup, Hermes Agent on a small VPS with my from-scratch v1 acting as a headless library that handles the cron jobs.
The agent that survived all three migrations is TARS. The substrate kept changing.
What makes TARS TARS:
- A SQLite schema with more than a dozen careful migrations
- About eighteen scheduled jobs that earn their keep
- A follow-up lifecycle with citation-gated closures
- An entity store with alias resolution
- A voice rewriter for the TARS-from-Interstellar cadence
- A frozen system prompt that doubles as a cache anchor
- A tailnet-only dashboard with cost rollups, an in-flight rail, and a unified brain search
- An Obsidian vault sync I trust to not race my human edits
None of that lives in the framework. It lives in the system I wrote on top of the framework. The first time I tried to put a pure framework install in front of my own memory and my own jobs, I ended up writing more glue than the system I was trying to replace.
OpenClaw is heavier and runs in my stack as a separate persona (CASE) for different work. Genuinely useful. But the cognitive load of "which agent do I talk to about this" is real, and TARS won that contest by being the one I trusted with my actual notes and calendar.
Hermes Agent is the substrate I happen to be running today. It's a good one. If a better one ships next month, I'll evaluate it. The system above the substrate is what stays.
What I take from this
I built TARS as a personal project. I'm not selling it, not open-sourcing it (yet), not pitching anyone on it. The experience of running an agent I actually depend on, not a demo, not a chatbot, has changed how I think about what's possible in this category.
A few takeaways for anyone considering doing the same:
-
Treat the agent and the framework as separate concerns. The framework is where it runs. The agent is the persona, the memory, and the jobs. If you can't swap one without losing the other, you've coupled them too tightly.
-
The cache anchor is not optional. A frozen system prompt and a byte-stable tool schema are the difference between sub-second turns and three-second ones. Most of the agent frameworks I've read don't talk about this. Read your provider response headers and find out what your hit rate actually is.
-
Multi-tier routing pays for itself within a week. Different call sites have different latency and quality requirements. Hardcoding one model for everything is a tax you pay every turn.
-
Memory is a schema, not a vector store. Hybrid retrieval over a well-designed SQLite schema, with FTS5 plus a vector column and a thoughtful rerank, beats a pile of embeddings in a managed vector DB for personal workloads. By a lot.
-
Make the dashboard tailnet-only. Single user, single network, no auth complexity. If you ever need multi-user, you can refactor. You probably won't.
This is the most over-engineered Telegram bot in the world. It is also the most useful tool I own.
The next time someone asks me what an AI agent is for, I'm going to point at the 5 AM voice note and the closed follow-up from last Tuesday, and not at any demo at all.
Related Articles
AI · May 2026
It's Not Just PMs
The traditional bottleneck in software development wasn't a lack of ideas; it was the technical gap between recognizing a problem and possessing the coding skills to solve it.
Read article →
AI · Apr 2026
The Morning I Stopped Paying for AI
I run two agents -- OpenClaw and Hermes -- locally and on a VPS hosted on Hetzner. Every day I use AI for research, code generation, agent workflows, and decision support. Until this morning, that meant API costs, rate limits, and a dependency on someone else's infrastructure.
Read article →